Utilizando a API do ChatGPT para gerar descritivos dinâmicos no Power BI
- Tessera Analysis
- 20 de abr. de 2023
- 7 min de leitura
O ChatGPT, desde seu lançamento, vem causando diferentes impressões nas redes sociais e na mídia sobre seus impactos diretos no futuro do trabalho. Fato é que, enquanto essas consequências se desenrolam na configuração de novos modelos de trabalho, seu uso tem mostrado a possibilidade de aumentar em muito a produtividade de profissionais que trabalham com análise de dados.
Desta vez, venho mostrar como ele pode ser usado para gerar descritivos/informativos (basicamente, textos escritos) para serem usados como complementos em dashboards no Power BI e demais aplicações de visualização que permitem interface com Python.
Por meio de sua API, podemos inputar listas, objetos e dataframes inteiros em nossas perguntas, para que seja feita sua interpretação pela IA.
Nosso objetivo neste artigo será realizar a leitura de uma base de dados de informações de clientes, agrupá-los por categoria e pedir ao ChatGPT para escrever um breve descritivo de cada categoria, pensando no usuário final. Ainda, toda a vez que essas categorias mudarem conforme a inserção de novos dados for ocorrendo, o descritivo também mudará.
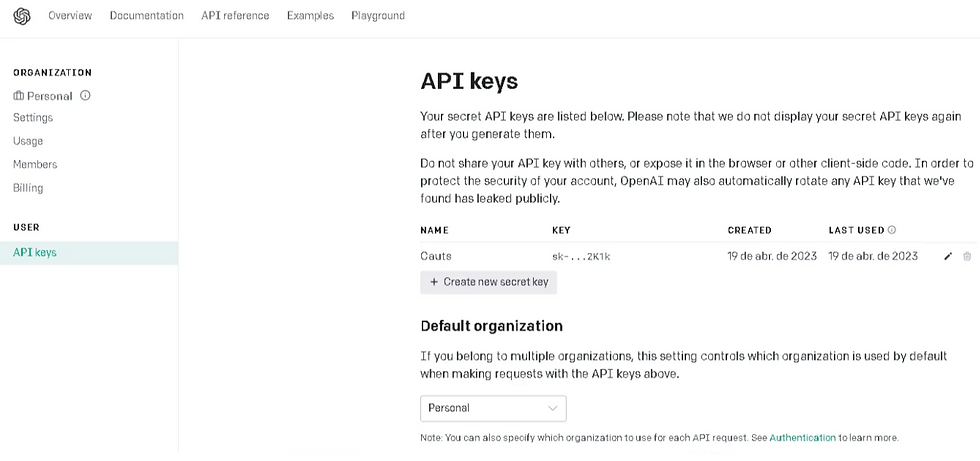
Para começar, você precisa obter uma chave de acesso à API. No link abaixo, basta acessar com sua conta e clicar em “Create new secret key”, copiando o código.
Estruturando o código em Python
A seguir. Vamos ao código necessário para conectarmos à API e realizarmos nossas primeiras perguntas:
#instalando a biblioteca da OpenAi
!pip install openai
#carregando bibliotecas
import pandas as pd
import openapi
#salvando a chave da API em um objeto
openai.api_key = "SUA_CHAVE_AQUI"
Como exemplo, utilizaremos uma base de dados de uma seguradora. Nela, possuímos informações socioeconômicas de seus clientes, além de seu Score de risco, o qual determina em termos gerais se aquela pessoa será uma boa ou má pagadora.
#lendo uma base de dados sobre clientes de uma empresa e seu score de credito
df = pd.read_csv('https://raw.githubusercontent.com/viniciusfjacinto/medium/main/dados_credito.csv', sep = ';')
df.head().T

Nossa tabela possui 10476 linhas (clientes) e 17 variáveis, as quais estão demonstradas acima. No próximo passo, iremos agrupar os clientes em categorias de A a E de acordo com seu score, utilizando a função pd.cut(). Depois, vamos separar apenas as variáveis numéricas de nossa base com df.select_dtypes(), para então calcular as médias por categoria com df.groupby().mean().
#agrupando os clientes em categorias de acordo com o valor do Score
df['SCORE_CATEGORIA'] = pd.cut(df['SCORE'], bins=[0, 30, 50, 70, 90, 100], labels=['E', 'D', 'C', 'B', 'A'])
#separando apenas as colunas numericas, e as unindo com a coluna de interesse
numeric_cols = df.filter(df.select_dtypes(include=['int', 'float']).columns)
df = pd.concat([numeric_cols, df['SCORE_CATEGORIA']], axis = 1)
#calculando a media por grupo
df_mean = df.groupby('SCORE_CATEGORIA').mean().round(2)
#visualiza o resultado
df_mean.T

Agora, vamos à API do ChatGPT, por meio da função openai.Completion.create(), iremos passar o dataframe df_mean e pedir para ele descrever brevemente cada grupo de clientes, em um estilo do tipo “Os clientes do Score A são os mais velhos, possuem renda complementar no valor de R$ 1.600,00 e estão há mais de 120 meses (10 anos) no último emprego… Os clientes do Score B…” e por aí em diante.
A função de pergunta possui os seguintes parâmetros:
engine: o modelo de linguagem específico que você deseja usar para gerar o texto. Existem vários valores possíveis para o parâmetro, cada um correspondendo a um modelo de linguagem específico treinado pela OpenAI. Alguns dos modelos disponíveis incluem:
text-davinci-003: o modelo de linguagem mais poderoso e completo disponível atualmente, capaz de gerar texto de alta qualidade em uma ampla variedade de tarefas de linguagem natural.
curie: um modelo de linguagem menor e mais rápido que ainda é capaz de gerar texto de alta qualidade em muitas tarefas de linguagem natural.
babbage: um modelo de linguagem menor projetado para tarefas de geração de texto mais simples, como respostas a perguntas e preenchimento de lacunas.
ada: um modelo de linguagem projetado especificamente para tarefas de classificação de texto, como análise de sentimentos e detecção de spam.
prompt: o texto inicial que é fornecido ao modelo para iniciar a geração do texto.
max_tokens: o número máximo de tokens (unidades básicas de linguagem) que o modelo pode gerar no texto resultante. Esse parâmetro ajuda a definir o tamanho máximo do texto gerado.
n: o número de saídas diferentes que você deseja que o modelo gere.
stop: um sinalizador opcional que indica ao modelo quando parar de gerar o texto. Quando o modelo encontra o texto indicado por este sinalizador, ele para de gerar texto. Se o valor for None, o modelo continuará gerando texto até atingir o número máximo de tokens definidos por max_tokens.
temperature: um valor que controla a "criatividade" do modelo na geração de texto. Um valor mais alto tornará o texto mais criativo e potencialmente menos coerente, enquanto um valor mais baixo fará o texto mais previsível e coerente.
Ao chamar openai.Completion.create(), o modelo gera uma ou mais conclusões com base nos parâmetros fornecidos e retorna o texto resultante.
Vamos definir nossa engine como a text-davinci-003 e realizar a nossa pergunta, pedindo ao modelo para descrever os dados por categoria de acordo com seus valores médios, de forma textual, clara e coesa, arredondando decimais e transformando valores em ‘$’. Faremos a pergunta em inglês para obtermos um melhor resultado, traduzindo para o português ao final do processo. Ainda, utilizarei um máximo de 1024 tokens para que o texto não fique muito extenso, gerando apenas uma resposta (n=1) e com uma criatividade limitada (temperature = 0.5).
Em linhas gerais, podemos ir gerando os textos e ajustando a pergunta para deixar nosso resultado o mais próximo possível do esperado. Após alguns ajustes, minha pergunta ficou assim:
“Describe the different profiles for each persona according to the index of {df_mean}. Talk about them in terms like ‘Person of X is more likely to have children and properties…, Person Y is younger than the others…’. Do comparatives. When talking about values, use the $ operator before the value, excluding decimals. When the value of column ‘OUTRA_RENDA_VALOR’ is 0 for a given ‘SCORE_CATEGORIA’, you don’t need to talk about it. Talk about all characeristics in mean terms of a group. Translate the output to Portuguese and masterize the coherence of the text.”
Ao fim, a API nos retornará um Json como output. Então, para visualizarmos a resposta, precisamos utilizar a função completion.choices[0].text .
Segue:
# define o modelo e a pergunta a ser feita
model_engine = "text-davinci-003"
prompt = f"Describe the different profiles for each persona according to the index of {df_mean}.\
Talk about them in terms like 'Person of X is more likely to have children and properties...,\
Person Y is younger than the others...'.\
Do comparatives.\
When talking about values, use the $ operator before the value, excluding decimals.\
When the value of column 'OUTRA_RENDA_VALOR' is 0 for a given 'SCORE_CATEGORIA', you don't need to talk about it.\
Talk about all characeristics in mean terms of a group.\
Translate the output to Portuguese and masterize the coherence of the text."
# requisição
completion = openai.Completion.create(
engine=model_engine,
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
temperature=0.5,
)
response = completion.choices[0].text
print(response)
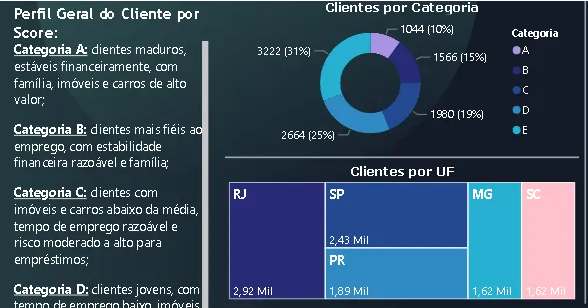
Persona A é a mais velha, com 47 anos, e tem a maior quantidade de filhos e de imóveis, além de renda extra de $1.600. Ela também possui a maior quantidade de carros, com um valor médio de $40.000, e trabalha há mais tempo, com 121,5 meses. Ela possui o maior score, 96,33.
Persona B é mais velha do que a Persona C e D, e mais nova do que a Persona A. Ela possui 1,61 filhos e 1,25 imóveis, além de renda extra de $1.000. Ela também possui 1,25 carros, com um valor médio de $69.500, e trabalha há 64,25 meses. Ela possui o segundo maior score, 80,92.
Persona C é o segundo mais velho, com 42 anos, e tem a segunda maior quantidade de filhos e de imóveis. Ela possui renda extra de $583 e possui 1 carro, com um valor médio de $62.224. Ela trabalha há 50,96 meses e tem um score de 59,15.
Persona D é mais nova do que a Persona E e C, e mais velha do que a Persona B e A. Ela possui 1,02 filhos e 0,64 imóveis, além de renda extra de $836. Ela também possui 1,08 carros, com um valor médio de $27.049, e trabalha há 21,16 meses. Ela possui o terceiro maior score, 39,22.
Persona E é a mais jovem, com 37 anos, e tem a menor quantidade de filhos e de imóveis. Ela possui renda extra de $0 e possui 0,74 carros, com um valor médio de $19.664. Ela trabalha há 14,15 meses e tem um score de 20,28.
Como o output nos mostra, o resultado obtido foi bastante satisfatório em atender nossos propósitos iniciais!
2. Implementando o código no Power BI
Importante: Se você nunca trabalhou com códigos em Python no Power BI, sugiro que siga o passo a passo deste tutorial para configuração inicial, pois é recomendável criar um ambiente virtual e instalar as bibliotecas ‘pandas’ e ‘openai’ nele, para que os códigos funcionem. Como não é o intuito deste artigo debruçar-se sobre este passo, seguiremos adiante.
No menu do Power BI, vamos em “Obter Dados”. Depois, vamos procurar “Script do Python”, conforme abaixo:

Ao abrir a janela, iremos inserir apenas os blocos essenciais de nosso código, dispensando as visualizações dos dados, como head(). Ainda, faremos uma modificação ao final, transformando o output em string de ‘response’ em um dataframe a ser entendido pelo Power BI, adicionando o seguinte termo ao final:
response = pd.DataFrame([response], columns=['output'])

Com isso, nosso código ficará assim:
import pandas as pd
import openai
openai.api_key = "SUA_CHAVE_AQUI"
df = pd.read_csv('https://raw.githubusercontent.com/viniciusfjacinto/medium/main/dados_credito.csv', sep = ';')
df['SCORE_CATEGORIA'] = pd.cut(df['SCORE'], bins=[0, 30, 50, 70, 90, 100], labels=['E', 'D', 'C', 'B', 'A'])
numeric_cols = df.filter(df.select_dtypes(include=['int', 'float']).columns)
df = pd.concat([numeric_cols, df['SCORE_CATEGORIA']], axis = 1)
df_mean = df.groupby('SCORE_CATEGORIA').mean().round(2)
# define o modelo e a pergunta a ser feita
model_engine = "text-davinci-003"
prompt = f"Describe the different profiles for each persona according to the index of {df_mean}.\
Talk about them in terms like 'Person of X is more likely to have children and properties..., Person Y is younger than the others...'.\
Do comparatives. When talking about values, use the $ operator before the value, excluding decimals.\
When the value of column 'OUTRA_RENDA_VALOR' is 0 for a given 'SCORE_CATEGORIA', you don't need to talk about it.\
Talk about all characeristics in mean terms of a group.\
Translate the output to Portuguese and masterize the coherence of the text."
# requisição
completion = openai.Completion.create(
engine=model_engine,
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
temperature=0.5,
)
response = completion.choices[0].text
#transformando o resultado em um df
response = pd.DataFrame([response], columns=['output'])
Agora, podemos carregar o dataframe responseem uma tabela no Power Query para depois criarmos nosso dashboard. Para tal finalidade, a visualização mais recomendada é a tabela, pois mantém a organização do texto de maneira adequada, com os espaçamentos entre cada tópico.
Por fim, o resultado final será parecido com esse:

Muito interessante, não é mesmo? O melhor de tudo é que ao atualizar a visualização, o texto também será atualizado. Suponha que de uma semana para outra a base aumentou em 1000 linhas/clientes; com isso, as médias irão se alterar e a análise também! Pense na imensa gama de possibilidades criativas unindo texto e dados para criar insights.
Pensando na experiência do usuário, sabemos que muitas pessoas irão preferir ler um texto explicativo sobre determinada análise exploratória do que interpretar gráficos complexos ou tabelas numéricas. Com isso, podemos facilitar em muito a tomada de decisão em certas situações.
Por Vinícius Felizatti, especialista em Data Science
Comentarios